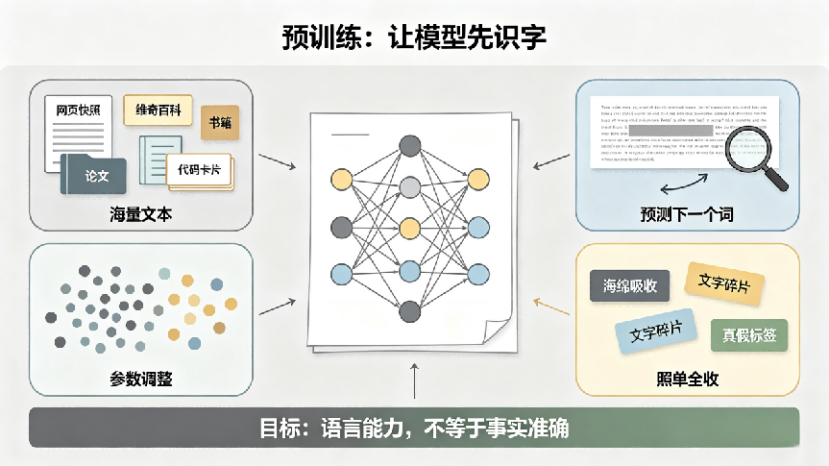
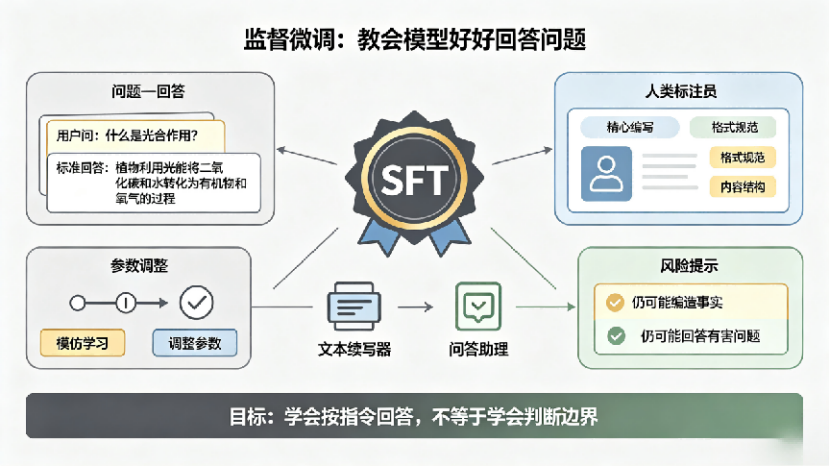
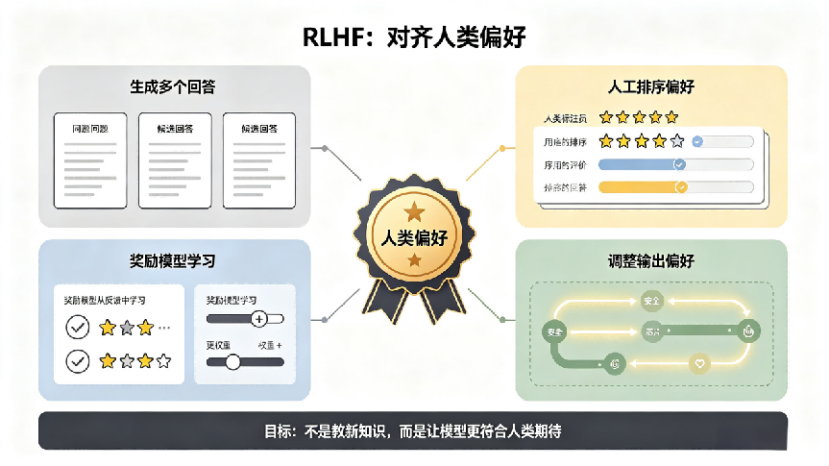
玩转AI——Gemini Notebook是我工作里最常用的AI之一,尤其是做PPT的时候
你以为它只是笔记本,其实能读资料、跑数据——Gemini Notebook来了
Google出品,把PDF、网页、表格和视频丢进去,不仅能读,还能总结、对比、画图、出成品
7月16日,Google正式把NotebookLM更名为Gemini Notebook。
名字像是换了块门牌,真正的升级却在后厨:部分付费用户已经能让它在安全云端环境中运行代码,资料分析从“帮你看懂”进化到“帮你算完”。
之前我们聊过桌面智能体、聊过文件生成工具,各有各的擅长。但Gemini Notebook切入的是另一个场景——你不是要它凭空编东西,而是要它先把你喂的材料吃透,再替你干活。
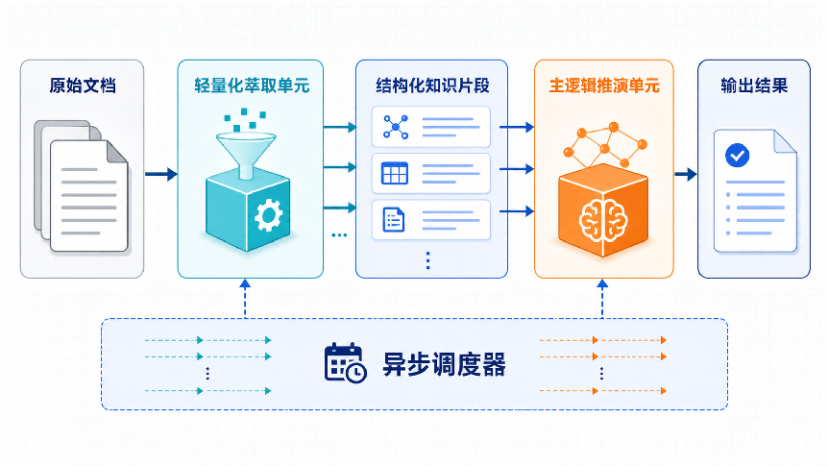
一句话概括新能力:把PDF、网页、表格和视频丢进去,Gemini Notebook不只帮你读,还能围绕原始资料做总结、对比、画图表、导出成品文件。
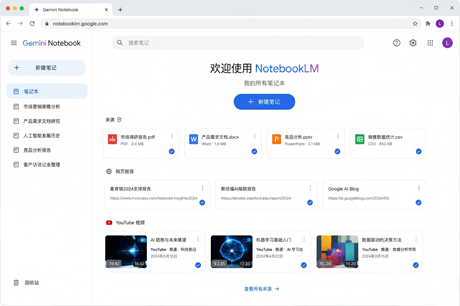
一、怎么用
第一步,建一本笔记。登录Gemini Notebook,新建项目,把PDF、Word、PPT、CSV、网页链接、YouTube视频或录音一次性丢进去。每个项目独立管理,资料不会在不同笔记之间乱串。
第二步,直接说人话。 别只问“总结一下”,试试这样下任务:“对比三份报告的共同结论和冲突点,每条都标出来源”“把这张CSV按月份分析,找出异常波动并解释原因”。回答会附资料引用,方便你回到原文核对。
第三步,到Studio里收成品。 你可以生成简报、思维导图、测验、音频解读、数据表或演示文稿。已开放云端计算能力的账号,还能让它运行代码、画图表、导出Excel、PPT、Word等文件。
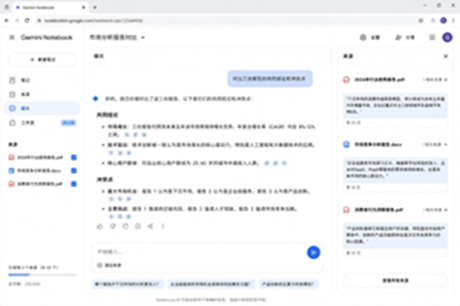
二、场景示例
备课做课件:上传教材、政策文件和几篇论文,让它先列知识框架,再生成课堂提问、随堂测验和讲解提纲。以前资料在文件夹里“各过各的”,现在终于肯坐下来开会了。
项目复盘:放入周报、会议纪要和数据表,要求它找出目标偏差、关键原因和下周行动。数据多时,再让它画趋势图,省掉手动筛表和拼结论。
快速吃透新领域:把行业报告、公开课视频和访谈录音放进一本笔记,先听音频概览,再沿着引用追问。适合调研、考试复习,也适合临时接到一个完全陌生的项目。
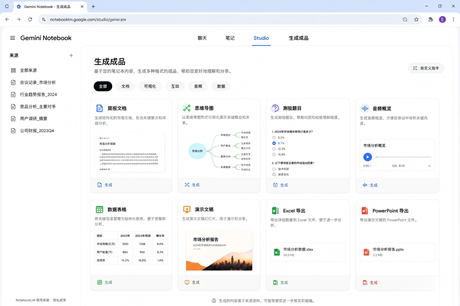
三、注意事项
改名不等于所有新功能同时到账。云端运行代码目前优先面向Google AI Ultra和部分Workspace商业用户,未来几周逐步覆盖Pro网页用户。普通用户仍可使用资料上传、基于来源问答和Studio内容生成功能。
AI回答有引用也不代表绝对正确,正式材料仍要回原文复核。上传内部资料前,确认好账号权限和分享范围。
最后聊两句
市面上AI工具分两类:一类帮你“凭空造”,一类帮你“从材料里挖”。Gemini Notebook稳稳站在后者。
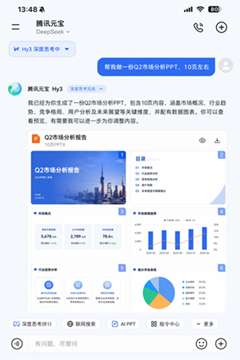
它不是让你跟AI闲聊,而是让你把资料扔进去、下命令、然后拿走成果。之前我们聊的桌面智能体是帮你操控电脑完成多步骤操作;腾讯元宝是一句话生成PPT和表格;百度秒哒是零代码搭应用。Gemini Notebook做的事不一样——它解决的是“围绕一堆资料深挖、追问、出成果”这件事。
改名只是开始。Gemini Notebook最值得关注的,是“资料库”开始长出真正的执行能力——从“读懂”到“算完”,Google把它塞进了一本笔记本里。**你最想把哪一堆资料塞进Gemini Notebook?评论区聊聊,我帮你把第一条指令写好。