玩转AI-”Hermes Desktop 使用报告:它干活,我摸鱼,双赢“
Hermes Desktop:一个让你从此“懒得亲自操作”的桌面智能体
开源免费、有记忆、能跨系统干活——关键是,真的很好用
各位被重复工作逼疯的小伙伴,今天聊一个开源桌面智能体——Hermes Desktop。
试用几天后,我决定把它装进主力电脑。这篇只讲怎么用:怎么让它干活、在哪儿薅它、有哪些注意事项。包教包会。
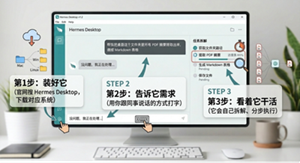
一、怎么让它干活:三步上手
第一步:装好它
官网搜 Hermes Desktop,下载对应系统(Win/Mac/Linux 都行)。装完打开,看到一个聊天框——别慌,它不是普通聊天机器人。
第二步:告诉它需求
用你跟同事说话的方式打字就行。例如:
“帮我把桌面这个文件夹里所有 PDF 摘要提取出来,做成 Markdown 表格”
“每天下午五点检查服务器 CPU,超80%就发邮件给我”
就当它是一个手速极快、但需要你交代清楚的实习生。
第三步:看着它干活
它会自己拆解任务、分步执行,做完告诉你结果。出错会尝试换方案,实在不行会停下来问你。
隐藏技能:长效记忆
它记住你让它做过的事。下次你说“再做一次”,它直接开干,不用重新教。适合每周都要跑的重复活。
收费吗? 公测基础功能全免费,高阶沙箱才收费。
二、在哪儿薅它:真香场景(远不止这些)
· 文献整理:对它说“监听‘待读文献’文件夹,新 PDF 自动提取标题、作者、摘要,添加到‘文献台账.md’。”每下载一篇,它自动记一笔。
· 定时跑脚本:“每晚10点,SSH 连测试服务器,运行 check_logs.sh,结果发我邮箱。”它自己连、跑、发,你安心睡觉。
· 爬网页:“打开这个网址,把页面上所有文章标题和链接爬下来,存到 Excel。”不用写一行代码。
· 整会议纪要:“把‘会议录音.txt’整理成结构化纪要,按‘议题-结论-待办’输出。”它归纳好,你复制粘贴。
当然,以上只是几个例子。它还能做批量文件重命名、格式转换、数据清洗、自动发消息……你想到的桌面自动化操作,它基本都能干。大模型内置的能力可不止四个,别被固定思维框住。

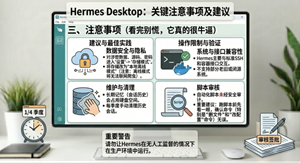
三、注意事项(看完别慌,它真的很牛逼)
说实话,再好的工具也有脾气。但千万别因为我写了几条注意事项就觉得它雷点多——恰恰相反,Hermes Desktop 是我见过最牛逼的开源桌面智能体之一,免费、有记忆、能跨系统干活,市面上很难找到第二个。只是为了让你们用得爽不翻车,该提醒的还是得提醒:
默认情况下它会把会话记忆存到云端,所以涉密数据、源码、密码建议去设置里改成本地离线模式(但离线后不能联网爬虫)。它只认标准 SSH 和容器接口,老旧闭源系统别指望它操作,更不要让它无人值守改生产环境。长期记忆会占硬盘,记得每季度手动清理一下历史会话。另外,它自动生成的脚本没有经过安全审计,建议你先看一眼、改一改再跑,尤其是删文件改配置的命令。
只要注意这几点,剩下的就交给它去卷吧。
Hermes Desktop 是开源圈少有的免费、有记忆、能跨系统干活的桌面智能体。整理文献、跑脚本、爬网页、整纪要——它能干的活比你想象的多得多。
别被几个小提醒劝退,它真的很牛逼。你只管动嘴,它替你动手。
你最想让它替你干什么?评论区告诉我。