
探新AI-你以为是夜宵的小龙虾,其实是革命的技术
先问你一个问题。
你手机里要是能跑 GPT-4,你愿意吗?
—— 如果代价是充一次电只能用 7 分钟。
这就是大模型最头疼的问题:太能吃了。吃的不是饭,是电。
你跟 ChatGPT 聊个天,一次对话的耗电量,是传统搜索引擎的 30 到 40 倍。
为什么这么费电?
因为现在的大模型有个 “死脑筋”:不管问题难易,一律全力运转。
你问它 “1+1 等于几”,它把 1750 亿个参数全拉出来遛一遍。你让它写篇博士论文,它也是用同样的力气。
就像一个大学教授,你问他几点了,他也要从相对论开始讲起。那有没有办法,让 AI 学会 “看人下菜碟”?
有。
答案藏在一种你绝对想不到的生物身上。
小龙虾教 AI 的事
这种生物就是 —— 小龙虾。
别笑。小龙虾的神经系统,是神经科学界的 “教科书级” 研究对象。
它有一个让所有 AI 工程师眼红的特性:反应极快,而且几乎不费电。
怎么做到的?
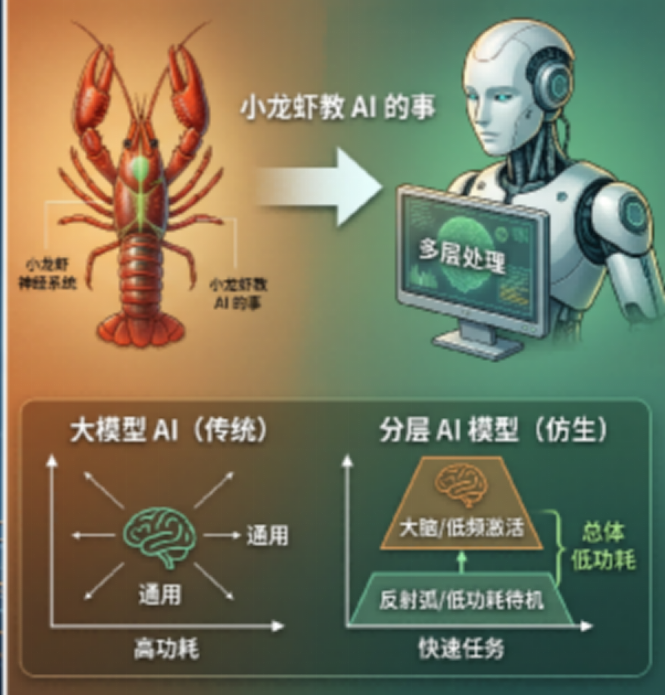
因为小龙虾的脑子是分层的:
- 底层(反射弧):负责 “逃!” 这种紧急任务,速度快、不费脑
- 高层(大脑):负责 “这玩意儿能吃吗” 这种复杂问题,速度慢、费能量
大部分情况,底层就把活干了。高层大多数时间在 “摸鱼”—— 低功耗待机。这就是小龙虾用一丁点能量活得好好的秘密。
而我们的大模型,永远在用 “高层大脑” 处理一切。
把小龙虾的 “分层大脑” 塞进 AI
2019 年前后,几个研究团队同时想到了一个点子:
能不能给 AI 也装一个 “反射弧”?
于是,一项叫 “早期退出机制” 的技术诞生了。原理不复杂:
在神经网络中间,开几个 “侧门”。
- 如果模型在前面几层就已经很有把握,就从 “侧门” 直接输出结果,后面的层根本不用跑
- 如果模型拿不准,才继续往下走,动用全部算力仔细判断
就像你做选择题:
第一眼就知道选 A,直接写答案,后面的选项看都不看
拿不准,才把四个选项都分析一遍结果准确率几乎不变,有时候反而更高。
这就是小龙虾技术的核心原理:不是让模型变 “笨”,而是让它学会该用力时用力,该省电时省电。
“小龙虾” 还能怎么进化?
早期退出” 只是第一代。真正的小龙虾技术,还有更狠的玩法。
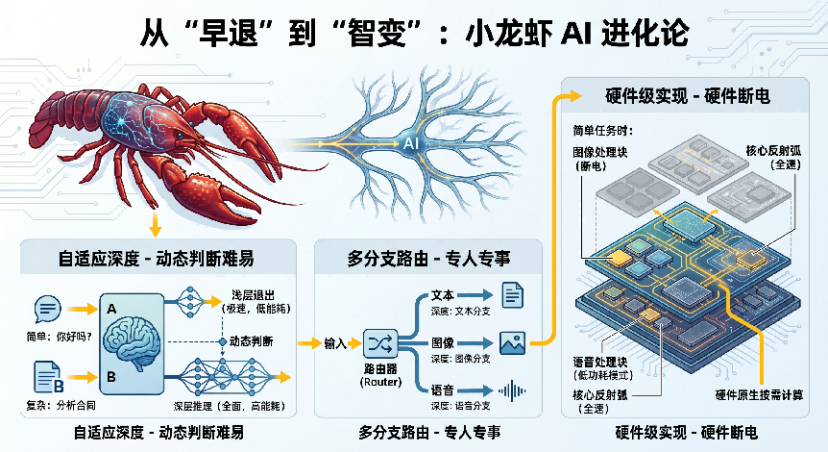
1. 自适应深度(Adaptive Depth)
不固定在第几层退出,而是根据输入难度动态调整。
- “你好吗” → 浅层退出
- 分析这份合同的风险条款” → 深层推理
模型会自动判断:这道题是 “1+1” 还是 “哥德巴赫猜想”。
2. 多分支路由(Multi-exit Routing)
不是一条直路,而是多个分支并行。
一个输入进来,先经过一个 “路由器”。路由器判断:这是图像、文本还是语音?
- 图像走图像分支
- 文本走文本分支
每条的 “深度” 不一样。就像医院分诊台:感冒去普通门诊,癌症去专家号。
3. 硬件级实现(Hardware Support)
最炸裂的是:Intel、IBM 已经在做芯片原生支持的小龙虾。
不是软件模拟,而是硬件层面就支持 “按需计算”—— 简单任务时,某些电路层直接断电。这才是真正的 “省电”。不是 “少用”,而是 “不用”。
现在的大模型竞赛,大家都在比谁更大、谁参数更多、谁算力更强。
但 “小龙虾” 告诉我们另一条路:
聪明的 AI,不是算得最多的那个,而是知道什么时候该算、什么时候可以不算的那个。
不是所有问题都需要全力解决。学会 “分层思考”,可能是更高级的智慧。毕竟 —— 连一只小龙虾都懂这个道理。
