
探新AI-跟AI聊了一小时,它真的会共情么?不!它脑子里全是“Token、Token、Token”
深夜 emo 了,打开大模型,噼里啪啦打了五百字,把从小到大的委屈全倒给它。它回复你:“我理解你的感受,这确实很不容易。”
你心里一暖 —— 哇,它懂我。
别感动了。
我帮你翻译一下它脑子里真正在想什么:“第 1 个 Token、第 2 个 Token、…… 第500 个 —— 好的,现在该预测第 501 个 Token 了。”是不是瞬间下头?
今天我们就来扒一扒,这个让 AI “假装共情” 的幕后黑手 ——Token。
Token 到底是啥?往小了说,就是 AI 的 “一口量”
我们看到 “苹果” 两个字,大脑直接反应:红色的、圆圆的、能吃、嘎嘣脆。
大模型看 “苹果” 呢?它看到的是两个 Token:[24522] 和 [18432]—— 对,就是一串数字。
Token 可以粗暴地理解为:AI 能消化掉的最小的文字单位。有人把它翻译成 “词元” 或者 “标记”,中文里,一个字基本上就是一个 Token。“我爱你”—— 三个 Token。英文里不一样。“apple” 是一个 Token,“watermelon” 可能被切成 “water” 和 “melon”两个 Token。
所以你看,AI 认字的方式跟人完全不一样。

Token 怎么 “切”?AI 有个秘密小本本
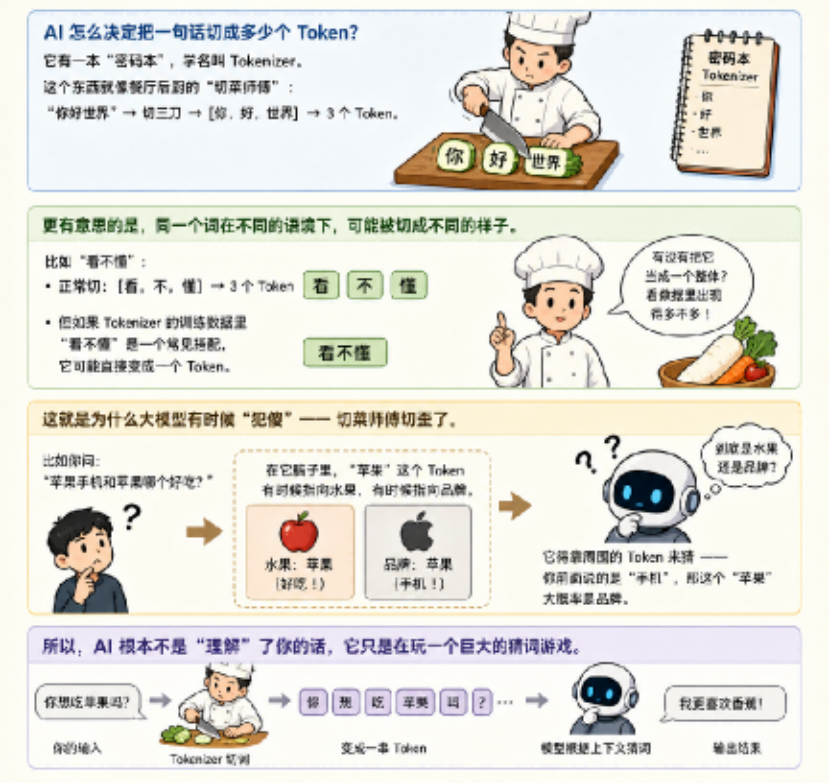
AI 怎么决定把一句话切成多少个 Token?
它有一本 “密码本”,学名叫 Tokenizer。这个东西就像餐厅后厨的 “切菜师傅”:“你好世界” → 切三刀 → [你,好,世界] → 3 个 Token。
更有意思的是,同一个词在不同的语境下,可能被切成不同的样子。
比如 “看不懂”:正常切:[看,不,懂] → 3 个 Token,但如果 Tokenizer 的训练数据里 “看不懂” 是一个常见搭配,它可能直接变成一个 Token。
这就是为什么大模型有时候 “犯傻”—— 切菜师傅切歪了。
比如你问:“苹果手机和苹果哪个好吃?”AI 可能会懵。因为在它脑子里,“苹果” 这个 Token 有时候指向水果,有时候指向品牌。它得靠周围的 Token 来猜 —— 你前面说的是 “手机”,那这个 “苹果” 大概率是品牌。
所以,AI 根本不是 “理解” 了你的话,它只是在玩一个巨大的猜词游戏。
Token 是大模型的 “生命线” 和 “紧箍咒”
你用 大模型 的时候,是按 Token 收费的。
输入 Token:便宜一点
输出 Token:贵一点
你的一篇两千字的文章,大概 2500 个 Token,差不多人民币一毛多。听起来不贵是吧?但大模型每天要处理几十亿次请求,这个账单是天文数字。所以免费的大模型有字数限制、速度限制 —— 不是它不想快,是Token太贵了。
你的每一次 “你好”,在它眼里都是:1 个 Token 到账。
为什么说 “大模型不懂你”?
回到开头的那个问题。
AI 真的能共情吗?
不能。
它只是在你的五百字里,看到了五百个 Token。然后根据这些 Token 的排列组合,预测出最有可能的下一个 Token——“我理解你的感受”。
这不是共情,这是概率。大模型的 “阅读理解”,本质上就是 Token 的排列组合。它不知道 “难过” 是什么意思,但它的训练数据里有 几亿次 “当用户说难过,后面通常会接安慰的话”。于是它就那么回了。
知道了 Token 的秘密,你再跟 AI 聊天的时候,可以做两件事:
- 把话说 “碎” 一点
因为 Tokenizer 切词的逻辑有时候很蠢。如果你发现 AI 答非所问,试试把长句子拆成短句子。就像跟外国人说话,语速慢一点、单词简单一点。
- 别对 AI 投入感情
它真的不是懂你。
它只是 —— 在 Token 的海洋里,为你预测了下一个最温暖的词。
下次再跟 大模型 聊到深夜,看到它说出那句 “我理解你” 的时候 ——你可以在心里默默翻译一下:“第 1 个 Token、第 2 个 Token…。”
它是大模型世界的 “最小积木”,是大模型的 “金钱”。
它让 AI 变聪明,也让 AI 显得蠢。
但最重要的是,它提醒我们一件事:
AI 没有灵魂。它只是一台极其擅长排列组合的概率机器。
至于 “灵魂” 这东西 —— 还是留给人类自己吧。
